What is coroutine? Complete explanation you can find in David Beazley’s presentation—“A Curious Course on Coroutines and Concurrency.” Here is my rough one. It is a generator which consumes values instead of emits ones.
>>> def gen(): # Regular generator
... yield 1
... yield 2
... yield 3
...
>>> g = gen()
>>> g.next()
1
>>> g.next()
2
>>> g.next()
3
>>> g.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>> def cor(): # Coroutine
... while True:
... i = yield
... print '%s consumed' % i
...
>>> c = cor()
>>> c.next()
>>> c.send(1)
1 consumed
>>> c.send(2)
2 consumed
>>> c.send(3)
3 consumed
As you can see yield statement can be used with assignment to consume values from outer code. An obviously named method send is used to send value to coroutine. Additionally coroutine should be “activated” by calling next method (or __next__ in Python 3.x). Since coroutine activation may be annoying, the following decorator is usually used for this purposes.
>>> def coroutine(f):
... def wrapper(*args, **kw):
... c = f(*args, **kw)
... c.send(None) # This is the same as calling ``next()``,
... # but works in Python 2.x and 3.x
... return c
... return wrapper
If you need to shutdown coroutine, use close method. Calling it will raise an exception GeneratorExit inside coroutine. It will raise also, when coroutine is destroyed by garbage collector.
>>> @coroutine
... def worker():
... try:
... while True:
... i = yield
... print "Working on %s" % i
... except GeneratorExit:
... print "Shutdown"
...
>>> w = worker()
>>> w.send(1)
Working on 1
>>> w.send(2)
Working on 2
>>> w.close()
Shutdown
>>> w.send(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>> w = worker()
>>> del w # BTW, it will not be passed in PyPy. You should explicitly call ``gc.collect()``
Shutdown
This exception cannot be “swallowed”, because it will cause of RuntimeError exception. Catching it should be used for freeing resources only.
>>> @coroutine
... def bad_worker():
... while True:
... try:
... i = yield
... print "Working on %s" % i
... except GeneratorExit:
... print "Do not disturb me!"
...
>>> w = bad_worker()
>>> w.send(1)
Working on 1
>>> w.close()
Do not disturb me!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: generator ignored GeneratorExit
That is all what you need to know about coroutines to start using them. Let’s see what benefits they give. In my opinion, a single coroutine is useless. The true power of coroutines comes when they are used in pipelines. A simple abstract example: filter out even numbers from input source, then multiply each number on 2, then add 1.
>>> @coroutine
... def apply(op, next=None):
... while True:
... i = yield
... i = op(i)
... if next:
... next.send(i)
...
>>> @coroutine
... def filter(cond, next=None):
... while True:
... i = yield
... if cond(i) and next:
... next.send(i)
...
>>> result = []
>>> pipeline = filter(lambda x: not x % 2, \
... apply(lambda x: x * 2, \
... apply(lambda x: x + 1, \
... apply(result.append))))
>>> for i in range(10):
... pipeline.send(i)
...
>>> result
[1, 5, 9, 13, 17]
Schema of pipeline

But the same pipeline can be implemented using generators:
>>> def apply(op, source):
... for i in source:
... yield op(i)
...
>>> def filter(cond, source):
... for i in source:
... if cond(i):
... yield i
...
>>> result = [i for i in \
... apply(lambda x: x + 1, \
... apply(lambda x: x * 2, \
... filter(lambda x: not x % 2, range(10))))]
>>> result
[1, 5, 9, 13, 17]
So what the difference between coroutines and generators? The difference is that generators can be connected in straight pipeline only, i.e. single input—single output. Whereas coroutines may have multiple outputs. Thus they can be connected in really complicated forked pipelines. For example, filter coroutine could be implemented in this way:
>>> @coroutine
... def filter(cond, ontrue=None, onfalse=None):
... while True:
... i = yield
... next = ontrue if cond(i) else onfalse
... if next:
... next.send(i)
...
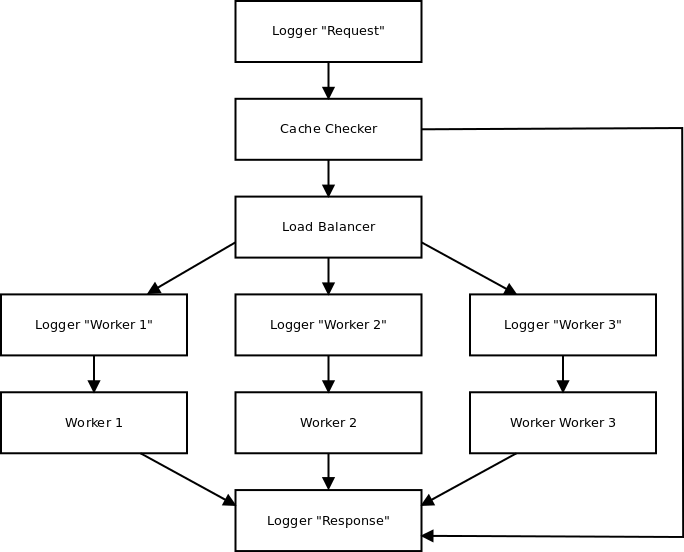
But let’s see an another example. Here is the mock of distributed computing system with cache, load balancer, and three workers.
def coroutine(f):
def wrapper(*arg, **kw):
c = f(*arg, **kw)
c.send(None)
return c
return wrapper
@coroutine
def logger(prefix="", next=None):
while True:
message = yield
print("{0}: {1}".format(prefix, message))
if next:
next.send(message)
@coroutine
def cache_checker(cache, onsuccess=None, onfail=None):
while True:
request = yield
if request in cache and onsuccess:
onsuccess.send(cache[request])
elif onfail:
onfail.send(request)
@coroutine
def load_balancer(*workers):
while True:
for worker in workers:
request = yield
worker.send(request)
@coroutine
def worker(cache, response, next=None):
while True:
request = yield
cache[request] = response
if next:
next.send(response)
cache = {}
response_logger = logger("Response")
cluster = load_balancer(
logger("Worker 1", worker(cache, 1, response_logger)),
logger("Worker 2", worker(cache, 2, response_logger)),
logger("Worker 3", worker(cache, 3, response_logger)),
)
cluster = cache_checker(cache, response_logger, cluster)
cluster = logger("Request", cluster)
if __name__ == "__main__":
from random import randint
for i in range(20):
cluster.send(randint(1, 5))
Schema of the mock
To start love coroutines try to implement the same system without them. Of course, you can implement some classes to store state in the attributes and do work using send method:
class worker(object):
def __init__(self, cache, response, next=None):
self.cache = cache
self.response = response
self.next = next
def send(self, request):
self.cache[request] = self.response
if self.next:
self.next.send(self.response)
But I dare you to find a beautiful implementation for load balancer in this way!
I hope I persuaded you that coroutines are cool. So if you are going to try them, take a look at my library—CoPipes. It will be helpful to build really big and complicated data processing pipelines. Your feedback is desired.